Recently I discovered that AS-override works in the opposite direction to what I thought! Now, this is largely academic as in most cases if you apply it to one peer you apply it everywhere, but I was dealing with a bit of a corner case and it caught me out as I had to mess about with (i.e. clear) a peer that I didn't really want to touch.
Cisco's config guides are a little bit ambiguous, saying:
"To configure a provider edge (PE) router to override the autonomous system number (ASN) of a site with the ASN of a provider, use the as-override command in VRF neighbor address family configuration mode. To restore the system to its default condition, use the no form of this command."
No mention whatsoever of in which direction the override happens. I always thought that a PE configured with AS override just didn't add the peer's AS to the AS_PATH when it received routes from the peer. It turns out I know nothing and that is not how it works at all.
In fact, as-override has no effect at all on received routes; it works only in the outbound direction. This makes sense, really, as the AS_PATH within carrier the carrier remains true (i.e. the service provider still gets to see what AS the routes originally came from). It's only when advertising routes out of the AS that as-override makes a difference, "overriding" the peer's ASN with the provider's.
But what does "overriding" mean? Let's take a look at some scenarios.
In a simple case where the AS_PATH (as seen by the provider) only contains a single entry and this corresponds with the peer's ASN, clearly the provider just replaces that with their own ASN. By "replace" I mean the peer's ASN is overwritten by the carrier's and then, as the route is advertised via eBGP, the carrier's ASN is added as normal. The route the peer receives, therefore, has an AS_PATH containing two copies of the carrier's ASN:
CE2#show ip bgp
BGP table version is 5, local router ID is 10.2.2.2
Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,
r RIB-failure, S Stale, m multipath, b backup-path, f RT-Filter,
x best-external, a additional-path, c RIB-compressed,
Origin codes: i - IGP, e - EGP, ? - incomplete
RPKI validation codes: V valid, I invalid, N Not found
Network Next Hop Metric LocPrf Weight Path
*> 10.0.1.0/24 10.2.2.1 0 100 100 i
*> 10.0.2.0/24 0.0.0.0 0 32768 i
CE2#
Prepended
So what if there are multiple copies of the peer's ASN at the start of the path? Well, as you might expect the whole topology doesn't suddenly tumble down. All copies of the peer ASN are replaced wih the carrier's ASN (after all, if we only replaced the first then the peer would still see it's own ASN and drop the update) before, again, adding the carrier's ASN as the route is advertised:
PE1#show ip bgp vpnv4 vrf cust1
BGP table version is 5, local router ID is 1.1.1.1
Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,
r RIB-failure, S Stale, m multipath, b backup-path, f RT-Filter,
x best-external, a additional-path, c RIB-compressed,
Origin codes: i - IGP, e - EGP, ? - incomplete
RPKI validation codes: V valid, I invalid, N Not found
Network Next Hop Metric LocPrf Weight Path
Route Distinguisher: 100:100 (default for vrf cust1)
*> 10.0.1.0/24 10.1.1.2 0 0 65000 65000 65000 i
*> 10.0.2.0/24 10.2.2.2 0 0 65000 i
PE1#
As observed on the PE, the route learned from CE1 has been prepended twice giving a total AS_PATH length of 3. All three of these 65000s will all be overridden when advertised towards CE2, creating the three 100s in orange and another copy of the local ASN (in red) will be added on egress as shown:
CE2#show ip bgp
BGP table version is 7, local router ID is 10.2.2.2
Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,
r RIB-failure, S Stale, m multipath, b backup-path, f RT-Filter,
x best-external, a additional-path, c RIB-compressed,
Origin codes: i - IGP, e - EGP, ? - incomplete
RPKI validation codes: V valid, I invalid, N Not found
Network Next Hop Metric LocPrf Weight Path
*> 10.0.1.0/24 10.2.2.1 0 100 100 100 100 i
*> 10.0.2.0/24 0.0.0.0 0 32768 i
CE2#
ASN Arbitrarily Contained in the AS_PATH
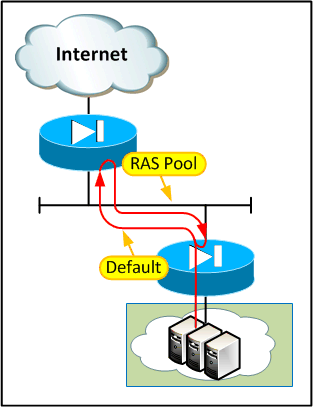
Another possibility exists where there are multiple AS involved. What if the customer connects to two different carriers who, in turn, connect to each other? This introduces the possibility that a customer route is learned from the other carrier, which then needs to be advertised out to the customer. The diagram below probably explains things better:
Thankfully, as-override doesn't seem to be too fussy (unlike remove-private-as in earlier IOS) and will replace the ASN wherever it appears in the path. It literally operates like a "find and replace all". Here's the AS_PATH from the PE's perspective showing the customer's ASN, followed by the other carrier's ASN:
PE1#show ip bgp vpnv4 vrf cust1
BGP table version is 6, local router ID is 1.1.1.1
Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,
r RIB-failure, S Stale, m multipath, b backup-path, f RT-Filter,
x best-external, a additional-path, c RIB-compressed,
Origin codes: i - IGP, e - EGP, ? - incomplete
RPKI validation codes: V valid, I invalid, N Not found
Network Next Hop Metric LocPrf Weight Path
Route Distinguisher: 100:100 (default for vrf cust1)
*> 192.168.0.0 172.16.1.2 0 200 65000 i
PE1#
And here we see the route from CE2's perspective, with the 65000 (customer's) ASN replaced by the provider's ASN (100 shown in orange), followed by the untouched transit AS (in blue) and finally the provider's ASN is added on egress (in red):
CE2#show ip bgp
BGP table version is 4, local router ID is 10.2.2.2
Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,
r RIB-failure, S Stale, m multipath, b backup-path, f RT-Filter,
x best-external, a additional-path, c RIB-compressed,
Origin codes: i - IGP, e - EGP, ? - incomplete
RPKI validation codes: V valid, I invalid, N Not found
Network Next Hop Metric LocPrf Weight Path
*> 192.168.0.0 10.2.2.1 0 100 200 100 i
CE2#
Don't forget - the other carrier will also have to use as-override, otherwise CE1 will discard CE2's routes.
In Coordination with "local-as"
Now, as you'd imagine as-override works in conjunction with "local-as" on the PE. The happy news is that when local-as is in use, the ASN specified in the local-as command is used to override the customer ASN (after all, we're pretending to be that ASN). The bad news is you get some funny looking AS_PATHs.
Let's take a simple case where two CEs connect to a single PE, actually configured as AS 50 but masquerading as AS100:
As you can see, on the PE, the route learned from CE1 shows the customer's ASN and also one copy of the pretend AS which is tacked on by default when using the local-as command:
PE#show ip bgp vpnv4 vrf cust1
BGP table version is 4, local router ID is 1.1.1.1
Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,
r RIB-failure, S Stale, m multipath, b backup-path, f RT-Filter,
x best-external, a additional-path, c RIB-compressed,
Origin codes: i - IGP, e - EGP, ? - incomplete
RPKI validation codes: V valid, I invalid, N Not found
Network Next Hop Metric LocPrf Weight Path
Route Distinguisher: 100:100 (default for vrf cust1)
*> 10.10.10.0/24 10.1.1.2 0 0 100 65000 i
PE#
If we look on CE2 we can see:
CE2#show ip bgp
BGP table version is 33, local router ID is 192.168.2.2
Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,
r RIB-failure, S Stale, m multipath, b backup-path, f RT-Filter,
x best-external, a additional-path, c RIB-compressed,
Origin codes: i - IGP, e - EGP, ? - incomplete
RPKI validation codes: V valid, I invalid, N Not found
Network Next Hop Metric LocPrf Weight Path
*> 10.10.10.0/24 10.2.2.1 0 100 50 100 100 i
CE2#
To explain this strange arrangement, we have:
- 100 - the pretend ASN (normal local-as behaviour, added on egress)
- 50 - the real ASN (normal local-as behaviour, added on egress)
- 100 - the pretend ASN (normal local-as behaviour, added on ingress from CE1)
- 100 - the pretend ASN used in place of the customer ASN (as-override)
Now, it's possible to set "
local-as" with the "
no-prepend" directive. This makes the situation
slightly cleaner in that the pretend ASN is no longer added as routes are received by the PE from the relevant peer. In other words you lose the
orange ASN out of the path, but notice that in this example the
no-prepend has to be applied on the PE's peering with CE1 in order to clean up CE2's BGP table....
Really, though, how many bodges do you want in play at once?
The Importance of SoO
Whenever altering the behaviour of something as important as BGP's loop prevention mechanism it is important to have a safety net. Unless you're very careful it's possible to introduce routing loops, particularly where multiple ISPs / ASNs are involved. Site of Origin, or SoO for short, provides just such a safety net.
The mode of operation is as follows:
- A SoO extended community is allocated for each customer site
- The SoO value is configured against each customer BGP peer within the PE router
- As routes are learned from a neighbour, the SoO extended community is attached to them to indicate their site of origin
- The PE checks any routes that are waiting to be advertised to a BGP peer and handles them according to the following rules:
- Any routes that are found to have the same SoO as the peer are not advertised to that particular peer
- Any routes that have a SoO community different to the peer's are advertised to that peer
- Any routes that do not have a SoO community attached are advertised
Now, SoO is occasionally overlooked as as-override often appears to work without it. Really, though, you are storing up problems for later.
Here's an example of SoO config on the PE:
router bgp 100
!
address-family ipv4 vrf cust1
neighbor 10.1.1.2 remote-as 65000
neighbor 10.1.1.2 activate
neighbor 10.1.1.2 as-override
neighbor 10.1.1.2 soo 100:1
neighbor 10.2.2.2 remote-as 65000
neighbor 10.2.2.2 activate
neighbor 10.2.2.2 as-override
neighbor 10.2.2.2 soo 100:2
exit-address-family
If there were two links into the same site (or into two sites joined by a backdoor network) then we would set the same SoO on both of its links. Since it uses an extended community (and this is a VRF so extended communities must be turned on) the SoO principle works across sites as well. It's important that different sites use different SoO values, otherwise they will not be able to learn each other's routes.
Problems Without SoO
There's one minor, almost cosmetic, quirk you get if you enable as-override without SoO:
If two CEs attach to the same PE then they will receive a copy of their own routes back from the PE.
This is a strange side-effect of the way update-groups work. Normally the PE would receive routes from both CEs, put together a list of updates and send them to both CEs - at this point each CE would see its own updates but would weed them out due to the AS_PATH containing the local ASN. With as-override enabled on the PE, the customer ASN is overridden with the provider's and the CE has no way to tell that the route was just echoed back.
Normally this doesn't matter as other mechanisms cause the locally injected route to be preferred (weight is set to 32768 for locally originated prefixes unless overridden, static routes generally have a better AD, etc) so it just looks a bit weird. There are cases where this does cause (rather drastic) problems, though. Take the following, not too far-fetched situation:
When the primary feed is up everything is great. The local preference of routes learned over the secondary feed is set to 50 by a route-map to ensure that they are less preferable than those received from the primary.
Let's break the primary feed and see what happens:
The withdrawals ripple through the network until CE2 is aware that the primary has gone away, decides to use the secondary and announces the route upstream. Seems legit so far...
Ah, no... this doesn't look right. The PE has echoed the route back to CE2 and, since the echoed route doesn't contain the local ASN and has a default local-preference of 100 it is now CE2's favourite.
Now we're in a right knot. CE2 has told the PE that it has a new route to use, but it contains the carrier ASN in the AS_PATH. The PE drops that as a loop, removes the route from its BGP table and sends a withdrawal message to CE2.
We are effectively back to the start where CE2 only has one option - it will take the route it is learning over the secondary feed and advertise it to the PE. Round and around we go...
There are a few tell-tale signs that this is happening. First of all there will be intermittent connectivity (usually in 30 second steps):
CE2#ping 10.10.10.1 repeat 1000
Type escape sequence to abort.
Sending 1000, 100-byte ICMP Echos to 10.0.1.1, timeout is 2 seconds:
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!................!!!!!!!!
!!!!!!!!!!!!!!!!!!!!
The next big giveaway is that when you run "show ip route" the age of the affected route(s) is always very low, typically under 30 seconds on standard BGP timers, and the path alternates between the same two next hops over and over:
CE2#show ip route 10.10.10.0
Routing entry for 10.10.10.0/24
Known via "bgp 65000", distance 20, metric 0
Tag 100, type external
Last update from 10.2.2.1 00:00:29 ago
Routing Descriptor Blocks:
* 10.2.2.1, from 10.2.2.1, 00:00:29 ago
Route metric is 0, traffic share count is 1
AS Hops 3
Route tag 100
MPLS label: none
CE2#show ip route 10.10.10.0
Routing entry for 10.10.10.0/24
Known via "bgp 65000", distance 20, metric 0
Tag 200, type external
Last update from 192.168.2.1 00:00:02 ago
Routing Descriptor Blocks:
* 192.168.2.1, from 192.168.2.1, 00:00:02 ago
Route metric is 0, traffic share count is 1
AS Hops 1
Route tag 200
MPLS label: none
CE2#
Finally, another good indication is that your BGP table version number is through the roof and continuously incrementing:
CE2#sh ip bgp
BGP table version is 51423, local router ID is 192.168.2.2
Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,
r RIB-failure, S Stale, m multipath, b backup-path, f RT-Filter,
x best-external, a additional-path, c RIB-compressed,
Origin codes: i - IGP, e - EGP, ? - incomplete
RPKI validation codes: V valid, I invalid, N Not found
Network Next Hop Metric LocPrf Weight Path
*> 10.10.10.0/24 10.2.2.1 0 100 100 200 i
* 192.168.2.1 0 50 0 200 i
CE2#
Note that you can also see the genuine and echoed routes in the BGP table (sometimes, re-check periodically).
It's possible to bodge together a route-map or prefix-list to 'fix' this, in fact just applying any unique route-map outbound on the PE will put the peer into a separate update-group which will bodge it into action. Please just use SoO, though - that's what it's there for!










.gif)
.gif)
.gif)
.gif)
.gif)
.gif)
.gif)
.gif)
{kind=link}
{kind=link}