A common requirement when lab / stress testing carrier kit is to have at least one copy of a full Internet routing table. While many people will use a network tester to generate, say, 700,000 routes programmatically, this is not really representative. Real Internet routes are not all the same size. They are not contiguous or predictable. They have different AS_PATHs of varying lengths. There are aggregates and specific prefixes, often both covering the same IP space. These factors may make no difference to your system under test, or they might make a huge difference - it's not unusual for TCAM to be partitioned or optimised by prefix length so surely it's best to test with the real thing, right?
This post shows how to build a fully populated and very fast BGP route server based on Ubuntu Bionic Beaver 18.04 LTS.
There are three main elements to this:
A daily dump of the RIPE RIB, which we will manipulate and shrink down to a single "view" ready for processing
A copy of RIPE's bgpdump and a (slightly tweaked) instance of the bgp_simple perl script which can be used to replay the processed dump file back to a listening BGP instance
An instance of BIRD, which is loaded up with routes by bgp_simple and can be used to re-advertise them (in a very fast and resilient fashion) to your systems under test.
This method overcomes a number of horrible issues - Trimming the RIB snapshot massively reduces the time to advertise the table, without compromising the number of prefixes. The bgp_simple instance is modified to reduce the amount of text output, which also increases speed. The BIRD instance sitting between bgp_simple and the system(s) under test increases robustness (BIRD will re-establish dropped BGP sessions whereas bgp_simple does not) and provides much faster update capability.
With these tweaks, a full table can be loaded into BIRD in around 2 minutes and, once fully loaded, BIRD can advertise the full table onward in a few seconds.
Topology
In this setup we will assume our route server will be 10.0.0.1 in AS 65001 and the system under test will be 10.0.0.2 in AS 65002.
Host Setup
This guide starts with a fresh Ubuntu 18.04 LTS instance. This can be a bare metal install, a VM or even a LXC container. You will need to set up this host's networking so that it can access the Internet, at least to begin with. Since this is a lab box, I'm being super sloppy and doing everything as root. You can mentally put "sudo" in front of everything if you'd rather.
First, update the packages and install a few necessary extras:
Now we need to get some Perl libraries via CPAN. First open CPAN:
cpan
Accepting the auto config should normally do what you want. Within there, run the following:
install CPAN reload CPAN
install Net::BGP
Exit out by pressing Ctrl-D
Now, edit /etc/bird/bird.conf as follows (replacing the existing "router id") config:
router id 10.0.0.1;
listen bgp address 10.0.0.1; protocol bgp {
local 10.0.0.1 as 65001;
neighbor 10.0.0.2 as 65002;
multihop;
source address 10.0.0.1;
next hop self;
import all;
export all;
} protocol bgp {
local 10.0.0.1 as 65001;
neighbor 192.2.0.1 as 64999;
multihop;
source address 10.0.0.1;
next hop self; passive;
import all;
export none;
}
Now, restart BIRD as follows:
service bird restart
At this point you should have BIRD running (you can check its status by running "birdc" and running some "show" commands - if your system under test is already configured you should see the peer come up). Next, we will set up bgp_simple to load the table into BIRD.
Before we can do that we need to download a few things:
Pick one of the IPs listed at random and filter down for just that neighbour. You can repeat this process using different addresses on different route servers if you'd like to simulate getting a table from two providers. In this example, we'll use 185.210.224.254, but any should be just as good.
This takes a looooong time, perhaps 25 minutes on a rubbish PC. Grab a cuppa.
Everything up until here will still be there after a reboot, the parts that follow will need to be re-run each time the route server gets rebooted.
Almost there, we need to add the unroutable test address onto the loopback interface: ip address add 192.2.0.1/32 dev lo
Finally, we will make some minor tweaks to bgp_simple:
cd bgpsimple
Edit bgp_simple.pl and comment out lines 640-649 - this prevents the script echoing all 700,000 routes to the console as they are advertised (complete with their AS_PATH, MED, etc).
Now run an instance of "screen" to keep bgp_simple running after your CLI session ends:
The script should connect and, after a short pause, tell you that it is advertising its routes to the peer. After a couple of minutes you should see a message to say the advertisement is complete.
At this point you can break out of screen using Ctrl-a, followed by "d" (reconnect later using "screen -r").
Finally, run "birdc" and execute "show route count" to confirm how many routes you are seeing. Once BIRD is loaded up it can blow a table down to a peer in seconds and can be configured for as many peers as you like.
I've recently been test driving a Cisco NCS 55A2, which has 24 x 1/10 Gbps and 16 x 1/10/25 Gbps ports. However, I ran into a problem where the 1/10/25 Gbps ports would not rate adapt down to 10 Gbps. There is no "speed" configuration under the port and seemingly nothing useful under controllers relevant to 25G ports.
I eventually got the answer from Cisco engineering but since I couldn't find this documented anywhere on the Internet I thought it might be worth preserving it here for prosperity!
Theory
Unlike 1/10G operation where the device just detects what optic is inserted then presents the appropriate GigabitEthernet or TenGigabitEthernet interface, 1/10/25G ports need to be hard set into either 1/10G or 25G mode. Frustratingly, when it comes to 25 Gbps ports, the NCS platforms set this in groups of four ports, each of which is referred to as a"quad". In another confusing move, Cisco has decided to put the quad config in a completely different place to very similar things such as the config to break out 40/100G ports into 10/25G members.
Configuration
As we can see here, the 1/10/25G ports default to 25G mode, reflected in their TFx/x/x/x naming:
Now, let's configure the first four 25G ports into 1/10G mode. The configuration lives under the "hw-module" branch, and quads are numbered from 0 (up to 3 on this platform). To set the first four ports into 1/10G mode:
If you're sick and tired of re-cabling your lab every time you want to try out a new topology then you should probably consider using a QinQ tunnelling switch instead. With a QinQ switch at the heart of your lab network it's possible to stand up completely arbitrary topologies with very little effort, no re-cabling and even set it up from a remote location.
In this post I'll walk through setting up a Cisco 3560 to act as a central QinQ switch and how to set up a few example topologies. This can also be done on older / lower spec switches using the same concepts - 802.1Q tunnelling is supported in most of the gear you'll find on eBay.
Theory
Service providers like to aggregate as many customers onto a single link as possible - otherwise they can't be price competitive. Customers want circuits that allow them to not only trunk VLANs but to use and and all of the 4095 possible VLAN IDs without having to check with their service provider first.
One (adequate) way to do this is to extend the notion of VLANs. We all know VLANs separate a LAN into multiple logical partitions using a VLAN identifier tag - QinQ takes that to the next level by stacking 2 VLAN tags on top of each other. If the service provider assigns a VLAN to each customer then they can be used to segregate customers from one another as follows:
Note here that both customers use VLAN 10, however they each get their own VLAN 10 independent of any other customer's. Customers can use any VLAN numbers they like, irrespective of what other customers or the provider has chosen to use.
In service provider parlance, the first (or outer) VLAN tag is the Service Provider VLAN (or S-VLAN). A customer's VLAN which get tunnelled through is called Customer VLAN (or C-VLAN). There is a hierarchy in that one S-VLAN may have multiple C-VLANs, while a C-VLAN can only have one parent S-VLAN. VLAN IDs can be re-used across customers, however customer A's VLAN 10 is different to customer B's VLAN 10.
For our lab setup we will do exactly the same thing, but locally on a single switch. 802.1Q tunnelling not only allows us to connect trunks to each other over a VLAN but also, optionally, control protocols such as LACP, spanning tree, CDP and so on can also be tunnelled through, giving the impression that the end devices are actually attached to each other rather than through a switch.
Physical Topology
Here's a simple lab setup - 2 PCs, 2 routers, 2 firewalls and 2 switches (plus our QinQ switch):
Basically, we just need to plug all the devices into the QinQ switch. Use as many ports as you have available in the QinQ switch and be sure to label them up with descriptions! Sensibly, though, you will really want a minimum of 4 ports for a switch and at least 3 for a firewall. You can get most of the functionality you want with using sub-interfaces on a router so in a pinch you can usually get away with having single links if need be. It's all about giving yourself the maximum flexibility.
Initial Setup
Before we even begin with the configuration proper, we have to work around a dopey default behaviour in Cisco switches. Straight out of the box most Catalyst switches have a layer 2 switching MTU of 1500 for both Fast Ethernet and Gigabit Ethernet ports. This needs to be overridden to allow full size frames to be passed through with a VLAN tag still attached.
Adjust the maximum MTU for Fast Ethernet ports as follows:
Lab-QinQ(config)#system mtu 1998 Changes to the system MTU will not take effect until the next reload is done
Note - different switches have different maximum values. Use the "?" key to see what your device will go to and pick the maximum
Adjust the maximum MTU for Gigabit Ethernet ports as follows:
Lab-QinQ(config)#system mtu jumbo 9000 Changes to the system jumbo MTU will not take effect until the next reload is done
Again, different devices may have different maximum values so use the "?" key to find how far you can set this.
Now, as it says, reboot the switch to make the changes stick.
Once the switch is back up and running, the next job is to create your "provider" VLANs. Note - these VLANs will not be visible to your "customer" topology so it's good to pick a range of consecutive VLAN IDs. I like to start at 100 and work up. Note that each of these VLANs needs to have its MTU increased from the default to allow transport of full size frames with the additional VLAN tag:
Lab-QinQ(config)#vlan 100 Lab-QinQ(config-vlan)# name xconnect100 Lab-QinQ(config-vlan)# mtu 1900 Lab-QinQ(config-vlan)#exit
You will need one VLAN for each virtual connection between devices - I usually throw 20 in and add more later if required.
Finally, for every port where you will attach a device, set the switchport into 802.1Q tunnel mode, and enable all the protocol tunnelling options:
As you can see, VLAN 101 is used to "connect" PC1 to SW1 port Gi1/4, while VLAN 102 is used to "connect" SW1 port Gi1/1 to R1 port Fa0/1. Thanks to the protocol tunnelling config, SW1 and R1 believe they are directly connected:
R1#show cdp neighbors Capability Codes: R - Router, T - Trans Bridge, B - Source Route Bridge S - Switch, H - Host, I - IGMP, r - Repeater, P - Phone, D - Remote, C - CVTA, M - Two-port Mac Relay
Device ID Local Intrfce Holdtme Capability Platform Port ID SW1 Fas 0/1 168 R S I WS-C6503- Gig 1/1
MAC entries are learned as if the devices were directly attached and the router and PC can ping each other:
R1#ping PC1
Type escape sequence to abort. Sending 5, 100-byte ICMP Echos to 192.168.0.2, timeout is 2 seconds: !!!!! Success rate is 100 percent (5/5), round-trip min/avg/max = 1/1/1 ms R1#
This is a fairly simple example but as we're about to get into, way more complex topologies can be achieved using the same methods.
Slightly More Complex Setup
Let's mix things up a bit by building a topology with an HA pair of Juniper SRX firewalls, trunking VLANs down to a pair of switches, connected by an LACP link bundle (portchannel):
As with the other example, we simply assign a provider VLAN to each link:
I won't include the config here for each of these as it's a pure repetition of the earlier work - just make sure that your ports go into the right VLANs and everything should be fine.
Now we can see that the firewalls have come up in HA:
{primary:node0}
root@SRX-top> show chassis cluster status
Monitor Failure codes:
CS Cold Sync monitoring FL Fabric Connection monitoring
GR GRES monitoring HW Hardware monitoring
IF Interface monitoring IP IP monitoring
LB Loopback monitoring MB Mbuf monitoring
NH Nexthop monitoring NP NPC monitoring
SP SPU monitoring SM Schedule monitoring
Cluster ID: 1
Node Priority Status Preempt Manual Monitor-failures
Redundancy group: 0 , Failover count: 1
node0 100 primary no no None
node1 50 secondary no no None
Redundancy group: 1 , Failover count: 1
node0 100 primary no no None
node1 50 secondary no no None
The switches have bundled their ports and can see each other's device IDs:
SW-2#show lacp internal Flags: S - Device is requesting Slow LACPDUs F - Device is requesting Fast LACPDUs A - Device is in Active mode P - Device is in Passive mode
Channel group 1 LACP port Admin Oper Port Port Port Flags State Priority Key Key Number State Gi0/1 SA bndl 32768 0x1 0x1 0x112 0x3D Gi0/2 SA bndl 32768 0x1 0x1 0x113 0x3D
SW-2#show lacp neighbor Flags: S - Device is requesting Slow LACPDUs F - Device is requesting Fast LACPDUs A - Device is in Active mode P - Device is in Passive mode
Channel group 1 neighbors
Partner's information:
LACP port Admin Oper Port Port Port Flags Priority Dev ID Age key Key Number State Gi0/1 SA 32768 3037.a6ca.aa80 10s 0x0 0x1 0x112 0x3D Gi0/2 SA 32768 3037.a6ca.aa80 9s 0x0 0x1 0x113 0x3D
And, as before, CDP works fine:
SW-2#show cdp neighbor Capability Codes: R - Router, T - Trans Bridge, B - Source Route Bridge S - Switch, H - Host, I - IGMP, r - Repeater, P - Phone, D - Remote, C - CVTA, M - Two-port Mac Relay
Device ID Local Intrfce Holdtme Capability Platform Port ID SW-1 Gig 0/1 152 S I WS-C3560G Gig 0/1 SW-1 Gig 0/2 164 S I WS-C3560G Gig 0/2 SW-2#
Even UDLD is active and "sees" the device on the other end as if it were locally connected:
SW-1#show udld Gi0/1
Interface Gi0/1 --- Port enable administrative configuration setting: Enabled / in aggressive mode Port enable operational state: Enabled / in aggressive mode Current bidirectional state: Bidirectional Current operational state: Advertisement - Single neighbor detected Message interval: 7 Time out interval: 5
Message interval: 15 Time out interval: 5 CDP Device name: SW-2 SW-1#
As a side note, a lot of Cisco kit only supports long LACP timers (90 second failure detection, as opposed to 3 seconds for short) so if you are in this boat then consider using UDLD when configuring bundles over indirect links. This should reduce detection time to 45 seconds, which is still a bit rubbish but better than 90. By default, error-disable recovery is not active for UDLD so once UDLD takes a link down, it stays down - so you probably want to switch recovery on:
SW-1(config)#errdisable recovery cause udld
Simulating Failures
One of the more common uses for a lab environment is to test failovers. One of the more common failure types to want to simulate is a link failure, however this is not quite as straightforward with a QinQ switch in the middle as taking one port down does not make the other go down, e.g.:
If you want to simulate pulling a link, I find the best way is to use an interface range command. Let's say we want to remove the link between FW1 and SW1, simply specify an interface range on the QinQ switch containing the switch ports facing each of those two devices and shut them down at the same time:
Lab-QinQ(config)#interface range fa0/14, fa0/21 Lab-QinQ(config-if-range)#shut .May 30 12:55:30 UTC: %LINK-5-CHANGED: Interface FastEthernet0/14, changed state to administratively down .May 30 12:55:30 UTC: %LINK-5-CHANGED: Interface FastEthernet0/21, changed state to administratively down .May 30 12:55:31 UTC: %LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/14, changed state to down .May 30 12:55:31 UTC: %LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/21, changed state to down
The same technique can be used to simulate the failure of an entire cabinet or site, just select all the ports you need in a range and shut them down.
Another common test that you may want to perform is to simulate a "silent failure", i.e. where both ends see the link up but traffic is lost in the middle. This is good for checking how quickly and how well protocol heartbeats detect link problems (think LACP, UDLD, routing protocols, etc) and is definitely worth checking before you put services over carrier circuits or inter-DC links. To achieve this, simply set the provider VLAN on one of your ports to something unused:
For a while I've wanted to post about Juniper SRX chassis cluster - I had to do some in-depth troubleshooting on it once and found that the information I needed was scattered across several documents and proved tricky to bring together.
Anyway, a couple of weeks ago I found the time to create a YouTube video showing how to do the basic setup of a chassis cluster, how to tell it is working, how to manually fail over, how to recover a disabled node and finally how to remove the chassis cluster configuration. The video is here:
However, at just over half an hour long it's a bit unwieldy if you only want some of the information! For easy searching, I've decided to write this accompanying blog post.
Chassis Cluster Concepts
Chassis cluster is Juniper's hardware HA mechanism for the SRX series. The chassis cluster mechanism keeps configurations and connection state replicated between devices so that, in the event of a failure, a standby device can take over the functions of the cluster with little downtime.
When a pair of devices are configured for chassis cluster, a raft of new port types come into play:
Control (CTRL) - The key to chassis cluster - responsible for replicating configuration and state, liveness checks and other housekeeping tasks. The CTRL port is usually chosen by JunOS and is fixed for a particular hardware type.
Fabric (fab0 / fab1) - Used to carry traffic between devices when a port goes down on the active device and traffic enters the standby (or for ports configured only on one member device). The fabric port is also used to avoid split brain in the event of a control link failure - if CTRL goes away but fabric remains, the two devices know not to both go active. Fabric ports are configured manually and there may be up to 2 pairs.
Out of Band Management (fxp0 and fxp1) - Used to manage the individual devices. The fxp interfaces do not fail over when there is a mastership change and always belong to the specific member, allowing management access to both devices irrespective of which is master. fxp ports are usually chosen by JunOS and will be fixed for a given hardware platform.
Redundant Ethernet (reth) - When a port on each device is configured for the same purpose, it is called a redundant Ethernet or "reth" interface. The active member of a reth moves as mastership changes and when there are connectivity failures. An arbitrary number of reth interfaces may be configured, depending on how many ports are available.
The diagram below shows our topology:
Preparing for Chassis Cluster
When setting up a chassis cluster I strongly recommend completely blowing away the configuration on your devices first. SRX 100 (and potentially other platforms) do not let you have Ethernet switching configuration while in chassis cluster mode, so even the vanilla factory default configuration can upset chassis cluster. Just clear everything, set the root password then commit:
root> configure
Entering configuration mode
[edit]
root# delete
This will delete the entire configuration
Delete everything under this level? [yes,no] (no) yes
[edit]
root# set system root-authentication plain-text-password
New password:
Retype new password:
Once this is done on both devices, we can begin the chassis cluster configuration.
Enabling Chassis Cluster
The first task with chassis cluster is to choose a cluster ID (from 0 to 255, however 0 means "no chassis cluster"). The cluster ID must match between members. In most cases you can just pick 1 but when there are multiple clusters on the same layer 2 network you will need to use different cluster IDs for each cluster.
At the same time the cluster ID is applied, we must also apply the node ID. Each device must have a unique node ID within the cluster, in fact 0 and 1 are the only valid node IDs so in essence one device must be node 0 and the other node 1.
In order to take effect, the devices must be rebooted and this can be requested by adding the "reboot" keyword:
root> set chassis cluster cluster-id 1 node 0 reboot Successfully enabled chassis cluster. Going to reboot now.
Note: this is done from the exec CLI context, not the configuration context. Perform the same command on the second device but using node 1 in place of node 0.
Once the devices have rebooted, you will notice that the prompt has changed to indicate the node number and activity status ("primary"or "secondary"). For a brief period following boot, the status on both devices will show as "hold" - during this time the device refrains from becoming active while it checks to see if there is another cluster member already serving.
{primary:node0}
root>
and
{secondary:node1}
root>
Once the devices have entered this state, configuration applied to one device will replicate to the other (in either direction). From here the rest of the chassis cluster configuration can be applied.
Note: If the devices both become active, check that their control link is up.
Redundancy Groups
Redundancy groups are primarily used to bundle resources that need to fail over together. Resources in the same redundancy group are always "live" on the same member firewall as each other, while different redundancy groups can be active on the same or different devices to one another. This allows some resources to be active on one cluster member while others are active on the opposite device.
To begin with there is only one redundancy group, group 0, which decides which firewall is the active routing engine. As a best practice you should always influence which device will become master in the event of a simultaneous reboot. This is done by setting the priority as follows:
Note that group 0 is not and cannot be pre-emptive, i.e. a higher priority only takes effect when there is an election (i.e. at boot time), not if a higher priority device appears while a lower priority device is active.
Later on we will configure redundant Ethernet interfaces, which is where groups 1 and upwards come into play. We will create group 1 ready for the interfaces - note this can be set to pre-empt if you like:
Here I've set the priorities the same between the groups - it's very possible to have group 0 active on one device and group 1 active on the other, however it's messy, lots of traffic has to traverse the fabric link(s) and it increases your exposure - in that state, failure of either firewall would have some impact on connectivity whereas when they are aligned you could lose the standby with no impact to service.
For this reason, I don't configure pre-empt - that way all groups should be active on the same device unless manually tweaked. If you'd rather it be revertive, use this command:
{primary:node0}[edit]
root@SRX-top# set chassis cluster redundancy-group 1 preempt
Applying Configuration to Single Devices
While it's useful to have exactly the same configuration on the firewalls for most things, it is very useful to be able to keep some configuration unique per device. Good examples of this are the device hostname and management IP address.
This is achieved using groups called "node0" and "node1" which are applied per device using a special macro:
{primary:node0}[edit]
root# set groups node0 system host-name SRX-top
{primary:node0}[edit]
root# set groups node0 interfaces fxp0 unit 0 family inet address 172.16.1.1/24
{primary:node0}[edit]
root# set groups node1 system host-name SRX-bottom
{primary:node0}[edit]
root# set groups node1 interfaces fxp0 unit 0 family inet address 172.16.1.2/24 {primary:node0}[edit]
root# set apply-groups ${node}
What we've done here is to define a node0 group which defines the hostname and out of band IP for node 0, then the same for node 1. Finally, the apply group uses the "${node}" macro to apply the node0 group to node 0 and node1 to node 1.
Defining Fabric Interfaces
In order to allow traffic to traverse between the clustered devices, at least one fabric interface per node must be configured (up to two per node is allowed). In our case we will configure this up on port 5 so that it is adjacent to the other special purpose ports. There are two "fab" virtual interfaces on the cluster, fab0 associated to node 0 and fab1 associated with fab1:
{primary:node0}[edit]
root# set interfaces fab0 fabric-options member-interfaces fe-0/0/5
{primary:node0}[edit]
root# set interfaces fab1 fabric-options member-interfaces fe-1/0/5
Note that ports on node 0 are denoted by fe-0/x/x while ports on node 1 are denoted by fe-1/x/x. If you want a dual fabric (either for resilience or to cope with a lot of inter-chassis traffic in the event of a failover) then just add the second interface on each side in exactly the same way.
Redundant Ethernet (reth) Interfaces
In order to be highly available, each traffic interface needs to have a presence on node 0 and node 1 (otherwise interfaces would be lost when a failover occurs). In the SRX chassis cluster world, this pairing of interfaces is done using a redundant Ethernet or "reth" virtual interfaces.
The first step in configuring redundant Ethernet interfaces is to decide how many are allowed (similar to ae interfaces):
{primary:node0}[edit]
root# set chassis cluster reth-count 5
Next we configure the member interfaces that will belong to each reth (note: on higher end SRX this will be gigether-options or ether-options rather than fastether-options):
{primary:node0}[edit]
root# set interfaces fe-0/0/0 fastether-options redundant-parent reth0
{primary:node0}[edit]
root# set interfaces fe-1/0/0 fastether-options redundant-parent reth0
...and assign the reth to a redundancy group (mentioned earlier):
{primary:node0}[edit]
root# set interfaces reth0 redundant-ether-options redundancy-group 1
At this point the reth can be configured like any other routed interface - units, address families, security zones, etc. are all used in exactly the same way as a normal port.
For reference, here's the full configuration as used in the video:
set groups node0 system host-name SRX-top
set groups node0 interfaces fxp0 unit 0 family inet address 172.16.1.1/24
set groups node1 system host-name SRX-bottom
set groups node1 interfaces fxp0 unit 0 family inet address 172.16.1.2/24
set apply-groups "${node}"
set system root-authentication encrypted-password "$1$X8eRYomW$Wbxj8V0ySW/5dQCXrkYD70"
set chassis cluster reth-count 5
set chassis cluster redundancy-group 0 node 0 priority 100
set chassis cluster redundancy-group 0 node 1 priority 50
set chassis cluster redundancy-group 1 node 0 priority 100
set chassis cluster redundancy-group 1 node 1 priority 50
set interfaces fe-0/0/0 fastether-options redundant-parent reth0
set interfaces fe-0/0/1 fastether-options redundant-parent reth1
set interfaces fe-1/0/0 fastether-options redundant-parent reth0
set interfaces fe-1/0/1 fastether-options redundant-parent reth1
set interfaces fab0 fabric-options member-interfaces fe-0/0/5
set interfaces fab1 fabric-options member-interfaces fe-1/0/5
set interfaces reth0 redundant-ether-options redundancy-group 1
set interfaces reth0 unit 0 family inet address 10.10.10.10/24
set interfaces reth1 redundant-ether-options redundancy-group 1
set interfaces reth1 unit 0 family inet address 192.168.0.1/24
set security nat source rule-set trust-to-untrust from zone trust
set security nat source rule-set trust-to-untrust to zone untrust
set security nat source rule-set trust-to-untrust rule nat-all match source-address 0.0.0.0/0
set security nat source rule-set trust-to-untrust rule nat-all then source-nat interface
set security policies from-zone trust to-zone untrust policy allow-all match source-address any
set security policies from-zone trust to-zone untrust policy allow-all match destination-address any
set security policies from-zone trust to-zone untrust policy allow-all match application any
set security policies from-zone trust to-zone untrust policy allow-all then permit
set security zones security-zone untrust interfaces reth0.0
set security zones security-zone trust interfaces reth1.0
Checking and Troubleshooting
Now that the configuration is in place, we should verify its status. There are a number of commands we can use to check the operation of chassis cluster, probably the most frequently used one would be "show chassis cluster status":
{primary:node0}
root@SRX-top> show chassis cluster status
Monitor Failure codes:
CS Cold Sync monitoring FL Fabric Connection monitoring
GR GRES monitoring HW Hardware monitoring
IF Interface monitoring IP IP monitoring
LB Loopback monitoring MB Mbuf monitoring
NH Nexthop monitoring NP NPC monitoring
SP SPU monitoring SM Schedule monitoring
Cluster ID: 1
Node Priority Status Preempt Manual Monitor-failures
Redundancy group: 0 , Failover count: 1
node0 100 primary no no None
node1 50 secondary no no None
Redundancy group: 1 , Failover count: 1
node0 100 primary no no None
node1 50 secondary no no None
From this you can see the configured priority for each node against each redundancy group, along with its operational status (i.e. whether it is acting as the primary or secondary).
Another useful command to verify proper operation is "show chassis cluster statistics":
{primary:node0} root@SRX-top> show chassis cluster statistics Control link statistics: Control link 0: Heartbeat packets sent: 424101 Heartbeat packets received: 424108 Heartbeat packet errors: 0 Fabric link statistics: Child link 0 Probes sent: 834746 Probes received: 834751 Child link 1 Probes sent: 0 Probes received: 0 Services Synchronized: Service name RTOs sent RTOs received Translation context 0 0 Incoming NAT 0 0 <snip>
In this output we would expect to see the number of control link heartbeats to be steadily increasing over time (more than 1 per second) and the same for the probes. Usefully, if you have dual fabric links then it shows activity for each separately so that you can determine the health of both.
One of the most useful commands available (which sometimes in older versions was not visible in the CLI help and would not auto-complete but would still run if typed completely) is "show chassis cluster information":
{primary:node0}
root@SRX-top> show chassis cluster information
node0:
--------------------------------------------------------------------------
Redundancy Group Information:
Redundancy Group 0 , Current State: primary, Weight: 255
Time From To Reason
Apr 28 15:06:58 hold secondary Hold timer expired
Apr 28 15:07:01 secondary primary Better priority (1/1)
Redundancy Group 1 , Current State: primary, Weight: 255
Time From To Reason
May 3 12:59:58 hold secondary Hold timer expired
May 3 12:59:59 secondary primary Better priority (100/50)
Chassis cluster LED information:
Current LED color: Green
Last LED change reason: No failures
Control port tagging:
Disabled
node1:
--------------------------------------------------------------------------
Redundancy Group Information:
Redundancy Group 0 , Current State: secondary, Weight: 255
Time From To Reason
Apr 28 15:06:34 hold secondary Hold timer expired
Redundancy Group 1 , Current State: secondary, Weight: 255
Time From To Reason
May 3 12:59:54 hold secondary Hold timer expired
Chassis cluster LED information:
Current LED color: Green
Last LED change reason: No failures
Control port tagging:
Disabled
The brilliant part about this command is that it shows you a history of exactly when and why the firewalls last changed state. The "Reason" field is really quite explanatory, giving reasons such as "Manual failover".
Manual Failover
Failing over the SRX chassis cluster is not quite as straightforward as with some other vendors' firewalls - for a start there are at least 2 redundancy groups to fail over, but in addition to that the forced activity is 'sticky', i.e. you have to clear out the forced mastership to put the cluster back to normal.
So let's say we have node0 active on both redundancy groups:
{secondary:node1} root> show chassis cluster status <snip> Cluster ID: 1 Node Priority Status Preempt Manual Monitor-failures Redundancy group: 0 , Failover count: 0 node0 100 primary no no None node1 50 secondary no no None Redundancy group: 1 , Failover count: 2 node0 100 primary no no None node1 50 secondary no no None
We can fail over redundancy group 1 as follows:
{secondary:node1} root> request chassis cluster failover redundancy-group 1 node 1 node1: -------------------------------------------------------------------------- Initiated manual failover for redundancy group 1
Now when we check, we can see that node1 is the primary as expected but also its priority has changed to 255 and the "Manual" column shows "yes" for both devices. This indicates that node1 is forced primary and, effectively, can't be pre-empted even if that is set up on the group:
{secondary:node1}
root> show chassis cluster status
<snip>
Cluster ID: 1
Node Priority Status Preempt Manual Monitor-failures
Redundancy group: 0 , Failover count: 0
node0 100 primary no no None
node1 50 secondary no no None
Redundancy group: 1 , Failover count: 3
node0 100 secondary no yes None
node1 255 primary no yes None
If you have pre-empt enabled on the redundancy-group then you will need to leave it like this for as long as you want node1 to remain active. If not then you can clear the forced mastership out immediately:
Successfully reset manual failover for redundancy group 1
Just remember to do this for both (or all) redundancy groups if you want to take node0 out of service for maintenance.
Fabric Links and Split Brain
In addition to transporting traffic between cluster members when redundancy-groups are active on different members, the fabric link or links carry keepalive messages. This not only ensures that the fabric links are usable but is also used as a method to prevent "split brain" in the event that the single control link goes down.
The logic that the SRX uses is as follows:
If the control link is lost but fabric is still reachable, the secondary node is immediately put into an "ineligible" state:
{secondary:node1}
root> show chassis cluster status
<snip>
Cluster ID: 1
Node Priority Status Preempt Manual Monitor-failures
Redundancy group: 0 , Failover count: 0
node0 0 lost n/a n/a n/a
node1 50 ineligible no no None
Redundancy group: 1 , Failover count: 4
node0 0 lost n/a n/a n/a
node1 50 ineligible no no None
If the fabric link is also lost during the next 180s then the primary is considered to be dead and the secondary node becomes primary. If the fabric link does is not lost during the 180s window then the standby device switches from "ineligible" to "disabled". Even if the control link recovers, as shown here (the partner node changes from "lost" to "primary"):
{ineligible:node1}
root> show chassis cluster status
<snip>
Cluster ID: 1
Node Priority Status Preempt Manual Monitor-failures
Redundancy group: 0 , Failover count: 0
node0 100 primary no no None
node1 50 ineligible no no None
Redundancy group: 1 , Failover count: 4
node0 100 primary no no None
node1 50 ineligible no no None
Once 180s passes, the device will still go into a "disabled" state:
{ineligible:node1}
root> show chassis cluster status
<snip>
Cluster ID: 1
Node Priority Status Preempt Manual Monitor-failures
Redundancy group: 0 , Failover count: 0
node0 100 primary no no None
node1 50 disabled no no None
Redundancy group: 1 , Failover count: 4
node0 100 primary no no None
node1 50 disabled no no None
The output of "show chassis cluster information" makes it quite clear what happened:
May 7 16:46:38 secondary ineligible Control link failure
May 7 16:49:38 ineligible disabled Ineligible timer expired
From the disabled state, the node can never become active. To recover from becoming "disabled", the affected node must be rebooted (later releases allow auto recovery, but this seems to just reboot the standby device anyway and that idea rubs me up the wrong way).
Removing Chassis Cluster
In order to remove chassis cluster from your devices, just go onto each node and run:
root@SRX-bottom> set chassis cluster disable
For cluster-ids greater than 15 and when deploying more than one
cluster in a single Layer 2 BROADCAST domain, it is mandatory that
fabric and control links are either connected back-to-back or
are connected on separate private VLANS.
Also, while not absolutely required, I strongly recommend:
{secondary:node1}
root@SRX-bottom> request system zeroize
warning: System will be rebooted and may not boot without configuration
Erase all data, including configuration and log files? [yes,no] (no) yes
error: the ipsec-key-management subsystem is not responding to management requests
Sometimes it would be really useful to see what flows are active over a link, i.e. what is talking to what, but you don't have a netflow collector available (or the time to set one up). I was in this situation recently and discovered that it's possible to get most of the useful information out of netflow using just a Linux box and some scripting. Easy peasy.
1 - Configure Netflow on the Router / Firewall
There's not much to say about this, it varies from platform to platform, vendor to vendor, but you just need to set the device up to send Netflow version 5 to your "collector" box.
A couple of examples are here
Older IOS (12.x):
mls flow ip interface-full ip flow-export version 5 ip flow-export destination x.x.x.x yyyy interface Gix/x ip flow ingress mls netflow sampling
Juniper SRX:
set system ntp server pool.ntp.org set interfaces fe-0/0/1 unit 0 family inet sampling input set interfaces fe-0/0/1 unit 0 family inet sampling output set forwarding-options sampling input rate 1024 set forwarding-options sampling family inet output flow-server x.x.x.x port yyyy set forwarding-options sampling family inet output flow-server x.x.x.x version 5
2 - Capture the Netflow Packets
Use tcpdump / tshark / wireshark / whatever to capture the packets on the "collector" box. The only thing to be careful of is that you don't allow tcpdump to truncate / slice the packets, e.g.: tcpdump -i eth0 -s 0 -w capfile.cap udp port yyyy and not icmp
The capture can be done on any box which your sampler can forward traffic to and from which you can retrieve the file back to a *nix box with tshark installed. If you have tshark installed on the capture box then you can also use it to dump the flows out.
3 - Dump the Flow Data with tshark
This can be done on the collector box if tshark is available or can be done elsewhere if not. Basically we ask tshark to dump out verbose packet contents then use standard *nix utilities to mangle the output:
This prints out the flows as reported by your router / firewall in tab separated columns as follows: Source IP, Destination IP, Source port, Destination port, IP Protocol
Of course this can be tailored to match whatever fields interest you (for example you may want to include ingress and egress interfaces to show traffic direction or byte counts to get an idea of flow size) but this will cover the basics.
Setting up IPSec VPNs in AWS is pretty simple - virtually all the work is done for you and they even provide you with a config template to blow onto your device. There are only a couple of points to remember while doing this to make sure you get a good, working VPN at the end - in this post I'll quickly show the setup and how to troubleshoot some of the more likely snags that you could run into.
Setup - AWS End
To set up an IPSec VPN into an AWS VPC you require 3 main components - the Virtual Private Gateway (VPG), the Customer Gateway (CG) and the actual VPN connection.
The VPG is is just a named device, like an IGW. Create a VPG and name it.
Attach the VPG to your VPC so that it can be used.
Next we need to create a Customer Gateway (CG) profile:
This defines the parameters of the opposite end of the tunnel (i.e. our SRX firewall), most key being the IP address. For our simple case we'll just use static routing but BGP is also an option.
Next we create a VPN connection profile:
The VPN connection profile basically ties the other two objects together and defines the IP prefix(es) that will be tunnelled over IPSec to the other end.
Once this is created you can download configuration templates for various device types, in our case we want Juniper ERX:
At this point the AWS VPN configuration is basically complete. Download the configuration template and open it in something which handles UNIX style end of line markers (i.e. Notepad++, Wordpad) ready to configure the firewall end.
Setup - Juniper SRX End
Assuming some sort of working basebuild, the Juniper SRX configuration is almost a straight copy and paste from the configuration templates. There are a couple of key exceptions:
IKE interface binding (lines 54 & 173 at time of writing) - you should override this with the "outside" interface of your firewall. For xDSL this will probably be pp0.0, for Ethernet based devices it could be fe-x/x/x.0 or vlan.x
Routing (lines 134 & 253 at time of writing) - the config template does not contain the actual routes you will need, or even a sensible default such as 172.31.0.0/16 to cover the default VPC.
It's probably worth un-commenting the traceoptions lines to give some debugging output in the event of tunnel problems.
Once the template is applied you may have the desired connectivity, if not then read on...
Troubleshooting
Firstly, we need to check phase 1 of the VPN (IKE) is up:
root@Lab-SRX> show security ike security-associations Index State Initiator cookie Responder cookie Mode Remote Address 4862528 UP 53a352fbe8fbf11a 26d9edf2e3a2d371 Main 52.56.146.67 4862529 UP 901117dbc101ce98 a1c21584e8cd22e2 Main 52.56.194.28
This shouldn't be a problem as the template basically takes care of all the proposals and whatnot being correct. If there aren't 2 SAs in an UP state then check you put the right IP address into the AWS Customer Gateway configuration.
Next, we check IPSec is up:
root@Lab-SRX> show security ipsec security-associations Total active tunnels: 2 ID Algorithm SPI Life:sec/kb Mon lsys Port Gateway <131073 ESP:aes-cbc-128/sha1 49d38075 3543/ unlim U root 500 52.56.146.67 >131073 ESP:aes-cbc-128/sha1 b3b5474b 3543/ unlim U root 500 52.56.146.67 <131074 ESP:aes-cbc-128/sha1 4df0b3b 3543/ unlim U root 500 52.56.194.28 >131074 ESP:aes-cbc-128/sha1 2e1e40aa 3543/ unlim U root 500 52.56.194.28
This should show two tunnels in each direction (direction denoted by the "<" and ">"). Again, very little is likely to go wrong here as the template should cover everything.
Assuming that's good, we would now check IPSec statistics:
Ideally we want to see both encrypted and decrypted packets - if one way isn't working then probably the (would be) sender is at fault. Verify that the configuration template was fully applied.
Next we check the secure tunnel interface statistics - a good idea is to ping other end of the tunnel to see if the counters increase:
A working ping to the other end with counters incrementing really indicates that the tunnel is formed OK and able to carry traffic. If this works but "real" traffic doesn't then there is most likely some basic configuration missing:
Check Intra-zone Traffic Permitted
By default you can't pass traffic between interfaces of the same zone on the SRX. It's common not to have more than one routed interface in a zone so this is easily overlooked. Just add it as follows:
root@Lab-SRX# set security policies from-zone trust to-zone trust policy allow-all match source-address any root@Lab-SRX# set security policies from-zone trust to-zone trust policy allow-all match destination-address any root@Lab-SRX# set security policies from-zone trust to-zone trust policy allow-all match application any root@Lab-SRX# set security policies from-zone trust to-zone trust policy allow-all then permit root@Lab-SRX# commit
You should now see your "real" traffic causing the VPN statistics to increment, even if the hosts at each end cannot communicate with one another.
Check AWS Routing Table
One thing that is easily forgotten when creating a new VGW is that in order to use it, a route entry must exist for the subnet sending traffic via the VGW. This needs to be created manually:
Simply edit the routing table(s) applied to your network(s) and set the next hop for your tunnelled networks to be the VPG appliance. At this point you may find that traffic from AWS towards the SRX works but in the opposite direction it does not...
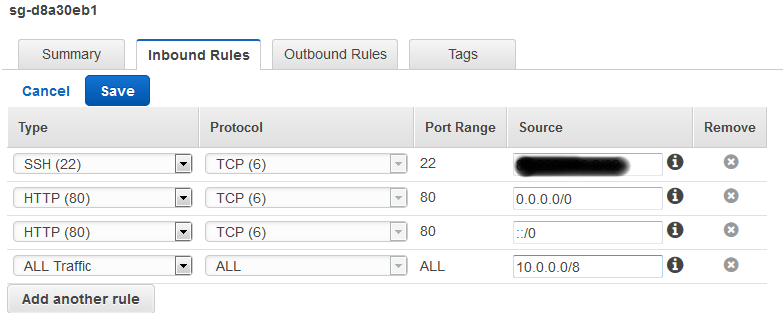
Check AWS Security Group
If at this stage you have one-way connectivity then almost certainly all you need to do is to allow the VPN range inbound on your security group(s). Remember that VPC security groups are stateful and all outbound traffic (and its replies) is allowed by default.
If required, simply add rules allowing the appropriate traffic from the IP block that is tunnelled back to the SRX. In this case to keep it simple we just allow open access:
If it still doesn't work, rollback the SRX config, blow away all the elements of the VPN and start again!