The payload was identical, in fact everything from the IP layer and up remained identical from one frame to the next. The only thing that varied was that the source and destination MAC addresses were swapped each time - clearly the packet was ping-ponging between two devices.
We checked the MACs and found they were legitimate - one was the local firewall, while the other was its default gateway - another ASA upstream towards the Internet.
This got our attention. First of all there was a routing loop, which is bad enough, but a packet should never be able to loop forever like that. That's why we have Time To Live (TTL) after all - the number which decrements by one each time a packet goes through a routed hop with the packet being thrown away when its value reaches zero. The key thing here is that the packet, including its TTL, was not changing at all so it never got removed from the system.
The cause of the routing loop was relatively easily found by looking at the source and destination IPs on the packet. The setup was as follows:

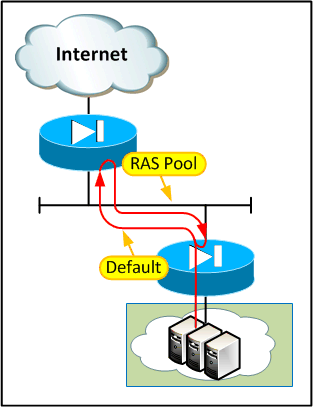
What had happened here was that a RAS user had connected to the tenant firewall using their IPSec client and started talking to some devices on the server LAN:

At some point the IPSec session had ended while an internal device was still sending traffic towards the user. This creates an interesting corner case:
{kind=link}
The routing is "correct" here - the multi-tenant firewall needs to route the RAS subnet via the tenant firewall so that RAS users can connect to shared resources. The tenant firewall needs to route the traffic outwards for it to hit the right crypto maps. The problem comes when a packet is destined for an IP in the RAS pool which is not associated with a live VPN session.
Our bodge to get us out of the immediate hole was to put a deny entry inbound on the mutli-tenant firewall for anything targeted at a RAS pool address. These packets should never make it onto the transit LAN as any legitimate traffic to that range would need to be tunneled via IPSec and therefore the multi-tenant firewall would see a public IP as the destination. After a lot of thinking we couldn't come up with a better answer than this and decided just to stop calling it a bodge.
OK, so first problem solved. Next question, why was the packet looping forever without ever reducing its TTL?
Root Cause
As it turns out this is by design on the ASA (and the good old fashioned PIX & FWSM before it). The idea is that if the firewall behaved like any other routed hop and decremented the TTL then it would be visible in traceroutes. To be fair if it did decrement TTL it would just appear as a black hole in the trace as the ASA doesn't really "do" unreachables unless you force its hand. This normally doesn't cause any problems, even if there is a routing loop. Take a typical deployment where an ASA is attached to a router as shown below:

{kind=link}
The problem comes when we have a pair of non-decrementing devices (ASAs) back to back at layer 2. Both devices route the packet but neither device decrements the TTL, so if there is a loop between the two it the packet will go around and around forever. Eugh...
The moral of the story is that it's probably best not to put ASAs back to back. I could have sworn I'd seen this setup in Cisco whitepapers before but, now that I look, I can't find it anywhere. The closest I can find is IOS firewall back to back with ASA or two ASAs with a server between. Perhaps there's a good reason for that :)
As with my situation, though, in most cases by the time you get to realise there is a problem the hardware has long since been bought, installed and is carrying live service. So what can you do?
Well, as noted above you can use ACLs to block potential loop traffic but in all honesty that just fixes by exception. You could be fairly liberal with what you block (e.g. drop all RFC 1918 addresses where you would expect to only see public IPs) but it's still imperfect.
Making the ASA decrement TTL
A better idea would be to have at least one of the ASAs decrement TTL. It's a bit uncomfortable to retro-fit but there is a way built in to ASA versions 8.0(3) and above using "set connection decrement-ttl" under a policy map. There are two different ways to do it, one is to adjust the "global_policy" policy map which applies to the entire device by default, or you can create a new policy map to apply to a single interface.
Here's how to apply it to the entire device:
policy-map global_policy
class class-default
set connection decrement-ttl
!
The effect is immediate as the global_policy is applied to all traffic by default. Alternatively, if you only want to apply it to specific interfaces, you can create a separate policy map and apply it as follows:
policy-map asa_workaround
class inspection_default
inspect dns preset_dns_map
inspect ftp
inspect h323 h225
inspect h323 ras
inspect netbios
inspect rsh
inspect rtsp
inspect skinny
inspect esmtp
inspect sqlnet
inspect sunrpc
inspect tftp
inspect sip
inspect xdmcp
inspect icmp
class class-default
set connection decrement-ttl
!
service-policy asa_workaround interface interface-name
The above is modeled on the standard default policy & inspections, if you've changed yours from default you probably don't need to be reading this!
Summary
So there you have it - ASAs back to back is a bit dangerous unless you take measures to protect against routing loops. This can be in the form of strict ACLs or by enabling TTL decrement, either globally or on specific interfaces.
References
Cisco guide to enabling traceroute through ASA
Cisco guide to modular policy framework on ASA
No comments:
Post a Comment